Exploring the Potential of Synthetic Data in Advancing AI Development and Applications
As artificial intelligence (AI) continues to evolve, it has become increasingly reliant on data to perform a range of tasks, from image recognition to natural language processing. However, with concerns around data privacy and the difficulty of obtaining quality data sets, synthetic data has emerged as a potential solution to these issues. In this article, we will explore the concept of synthetic data and its potential applications in AI.
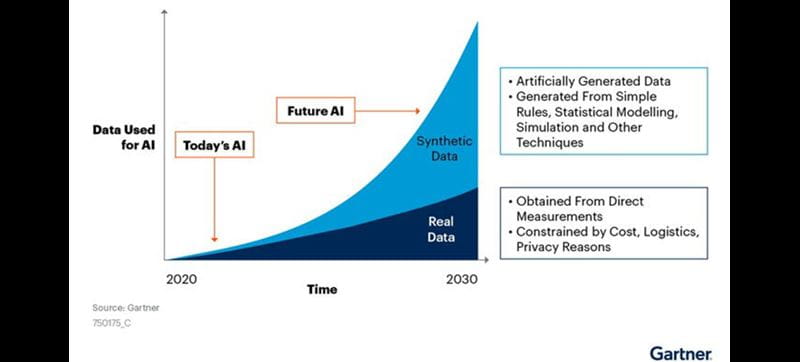
According to the Gartner, Synthetic data will completely overshadow real data in AI models by 2030.
What is Synthetic data?
Synthetic data is artificially generated data that imitates the statistical properties and structure of real-world data. It is created using algorithms and statistical models that simulate patterns found in real data sets. The process of generating synthetic data involves analyzing and extracting patterns and relationships from existing data sets, and then using those patterns to create new data that follows similar statistical distributions.
Synthetic data is often used for training and testing machine learning models when real-world data is limited or sensitive. It can also be used to augment real data sets to create larger and more diverse data sets. Additionally, synthetic data can be used to create privacy-preserving data sets by removing sensitive information from real data and replacing it with synthetic data that closely matches the original data.
While synthetic data can be useful in certain applications, it is important to ensure that it accurately represents the real-world data it is intended to mimic. Careful validation and testing are necessary to ensure that the synthetic data is appropriate for the intended use case.

Why is synthetic data a must-have and essential for the future of AI?
Synthetic data has become increasingly important for the future of AI for several reasons:
Data Availability: The availability of high-quality and diverse data is crucial for AI models to learn and generalize well. However, in many cases, real-world data may not be available, or it may be costly or time-consuming to collect. Synthetic data can help fill this gap by providing large volumes of high-quality and diverse data for training AI models.
Data Diversity: AI models trained on a limited amount of data may not generalize well to new scenarios or environments. Synthetic data can be used to create diverse training data that covers a wide range of scenarios and environments, leading to more robust and reliable AI models.
Data Privacy: Real-world data often contains sensitive or private information that cannot be shared or used for training AI models. Synthetic data can be generated from existing data sources without revealing any sensitive information, making it a valuable tool for data privacy and security.
Cost Efficiency: Collecting and labeling real-world data can be a time-consuming and expensive process. Synthetic data can be generated at a fraction of the cost, making it an attractive alternative for training AI models.
Faster Iteration: Synthetic data can be generated quickly and easily, allowing for faster iteration and experimentation in developing AI models.
Overall, synthetic data has become a must-have tool for AI development, as it provides a flexible and cost-effective way to generate high-quality training data for AI models.

What are the risks associated with the use of Synthetic data?
Synthetic data refers to data that is artificially generated using a variety of techniques, such as machine learning algorithms, statistical models, or simulations, rather than being collected from real-world sources. While synthetic data can offer several advantages, such as privacy protection, cost savings, and scalability, there are also some potential risks associated with its use. Here are some of the main risks:
Bias: Synthetic data may inadvertently introduce biases if the algorithms or models used to generate it are themselves biased. For example, if the training data used to generate synthetic data is biased, the resulting synthetic data may also be biased, perpetuating existing biases in the system.
Lack of diversity: Synthetic data may not accurately reflect the real-world diversity of data, which can limit the accuracy and generalizability of models trained on it.
Overfitting: Synthetic data may over fit to the specific characteristics of the training data, leading to poor generalization to new data.
Lack of transparency: Synthetic data is often generated using complex algorithms or models, making it difficult to understand how the data was generated and evaluate its quality.
Security: Synthetic data can still contain sensitive information that can be used to identify individuals or reveal confidential information, which can pose a security risk.
Legal and ethical concerns: The use of synthetic data may raise legal and ethical concerns around data ownership, consent, and privacy, particularly when it is used in applications that involve sensitive personal information.

Summing Up!
Synthetic data, or artificially generated data that mimics the statistical properties and structure of real-world data, is becoming increasingly important for the future of AI as it can address issues around data availability, diversity, privacy, cost efficiency, and faster iteration. However, careful validation and testing are necessary to ensure that the synthetic data accurately represents the real-world data it is intended to mimic.
Risks associated with the use of synthetic data include bias, lack of diversity, overfitting, lack of transparency, security, and legal and ethical concerns. Despite these risks, synthetic data has become a must-have tool for AI development, providing a flexible and cost-effective way to generate high-quality training data for AI models.